前面我們說明了如何使用預訓練模型推論以及訓練客製化物件偵測模型,而倘若我們要建立自己的資料集該如何進行呢? Hello AI World 專案中也提供了一個實用的工具,方便我們建立客製化資料集!

建立物件偵測資料集 (source: NVIDIA)
開始之前我們需要建立資料集的工作目錄,來儲存對應的影像資料。依照 Hello AI World 專案結構,建議可以在 jetson-inference/python/training/detection/ssd/data/ 路徑下建立一個資料夾來存放。並在此資料夾中建立一個名為 labels.txt 的文字檔,存放所有物件偵測的類別。舉例筆者建立一個 custom 的資料集目錄,並且建立標籤檔:
mkdir jetson-inference/python/training/detection/ssd/data/custom/
cd jetson-inference/python/training/detection/ssd/data/custom/
vi label.txt
在標籤檔中逐行輸入各個類別的名稱,例如:
Watermelon
Grapes
Pineapple
完成了前置作業進入 docker 容器的開發環境
cd ~/jetson-inference/
docker/run.sh
執行影像標註工具 camera-capture,後面帶入的參數 /dev/video0 則是選定從 Webcam 抓取影像資料,若使用 CSI Camera 則改為 csi://0
camera-capture /dev/video0
執行後會啟動 Data Capture Control 控制對話框以及一個即時預覽影像。在控制對話框的有選項可供調整:
labels.txt 檔案即可。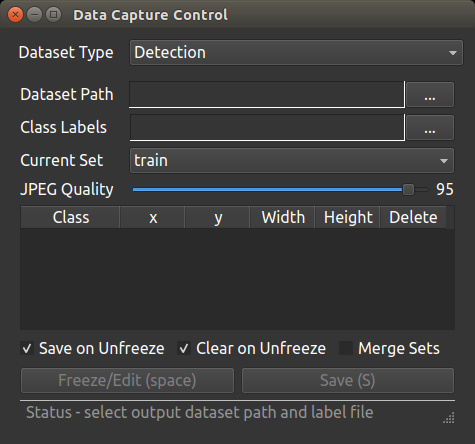
設定完成開始進行標註,要擷取當前影像點選 Freeze/Edit 鈕 (快捷鍵為空白鍵 space) ,即時預覽的影像就會被捕捉下來。此時可用滑鼠框選物件,每框選一個在控制對話框的類別清單就會多一個,可以選擇此物件的類別(class),或是微調位置與大小,抑或是要刪除皆可。當所有物件都被標註完成,即可按下 save 鈕(快捷鍵為 S),即完成了一張影像的標註。接下來就是花費時間建立完整資料集了!需要留意的是, camera-capture 的物件偵測資料是以 Pascal VOC 格式記錄的,若是要用於他處並不支援 VOC 格式的話,還需要另作轉換喔!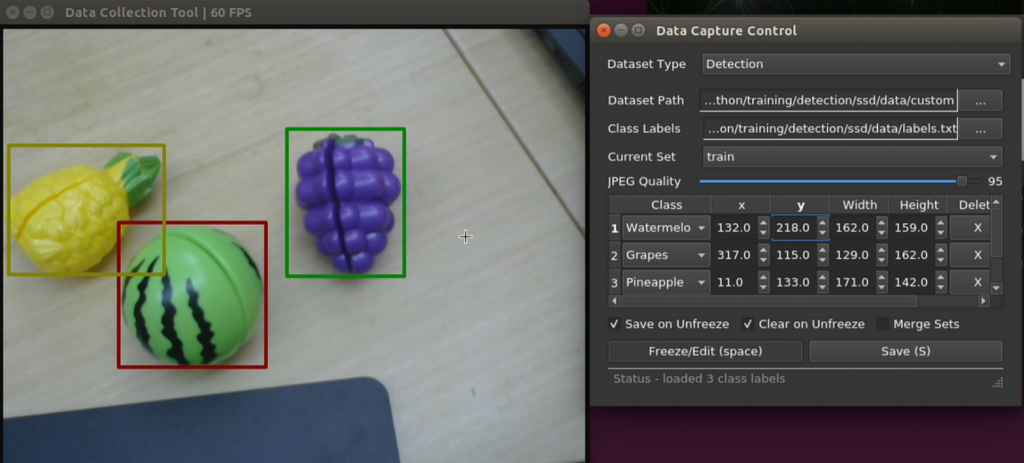
訓練模型的流程都和前一篇 【Day 20】Hello AI World (六):訓練自己的物件偵測模型 所述相同,唯獨不同之處在於訓練時需要額外帶入一個 --dataset-type=voc 參數,表示所給予的訓練資料是採用 VOC 格式記錄的。
cd jetson-inference/python/training/detection/ssd
python3 train_ssd.py --dataset-type=voc --data=data/<YOUR-DATASET> --model-dir=models/<YOUR-MODEL>
Hello AI World 的部分到今天就告一個段落了,其實該專案內容相當豐富,筆者也僅能挑選一些重點項目進行實作與心得提點,有興趣的開發者可以再多花一些時間到專案 Repo 上進一步探索,會相當有收穫的!

